ch8 集成学习
集成学习的思想
- 三个臭皮匠 顶个诸葛亮
- 头脑风暴
- 评审打分
总览
- Bagging
- 随机森林
- Boosting
- AdaBoost
集成学习(Ensemble Learning)是什么?
集成学习通过构建并结合多个学习器来完成学习任务,有时候也被称为多分类器系统、基于委员会的学习。能够提高模型的性能,降低模型选择不当的可能性。
集成学习使用一些方法来改变原始训练样本的分布,以构建多个不同的学习器,然后将这些多个学习器组合起来完成学习任务,通常能获得比单个学习器显著更优的泛化性能。
同质集成:
- 使用单一、任意的学习算法,但操纵训练数据以使其学习多个模型。
- Data1 ≠ Data2 ≠ … ≠ Data m
- Learner1 = Learner2 = … = Learner m
- 改变训练数据的不同方法:
- Bagging:对训练数据进行重采样(Resample)
- Boosting:对训练数据进行重加权(Reweight)
装袋算法 Bagging(bootstrap aggregating,自助聚集)
给定一个大小为n的训练集,通过从原始数据中有放回地抽取n个样本,创建个m大小为n的样本。大约有63.2%的原始数据会出现在每个抽样得到的数据集里,故有36.8%的数据未被采样。
要怎么用这36.8%的数据呢?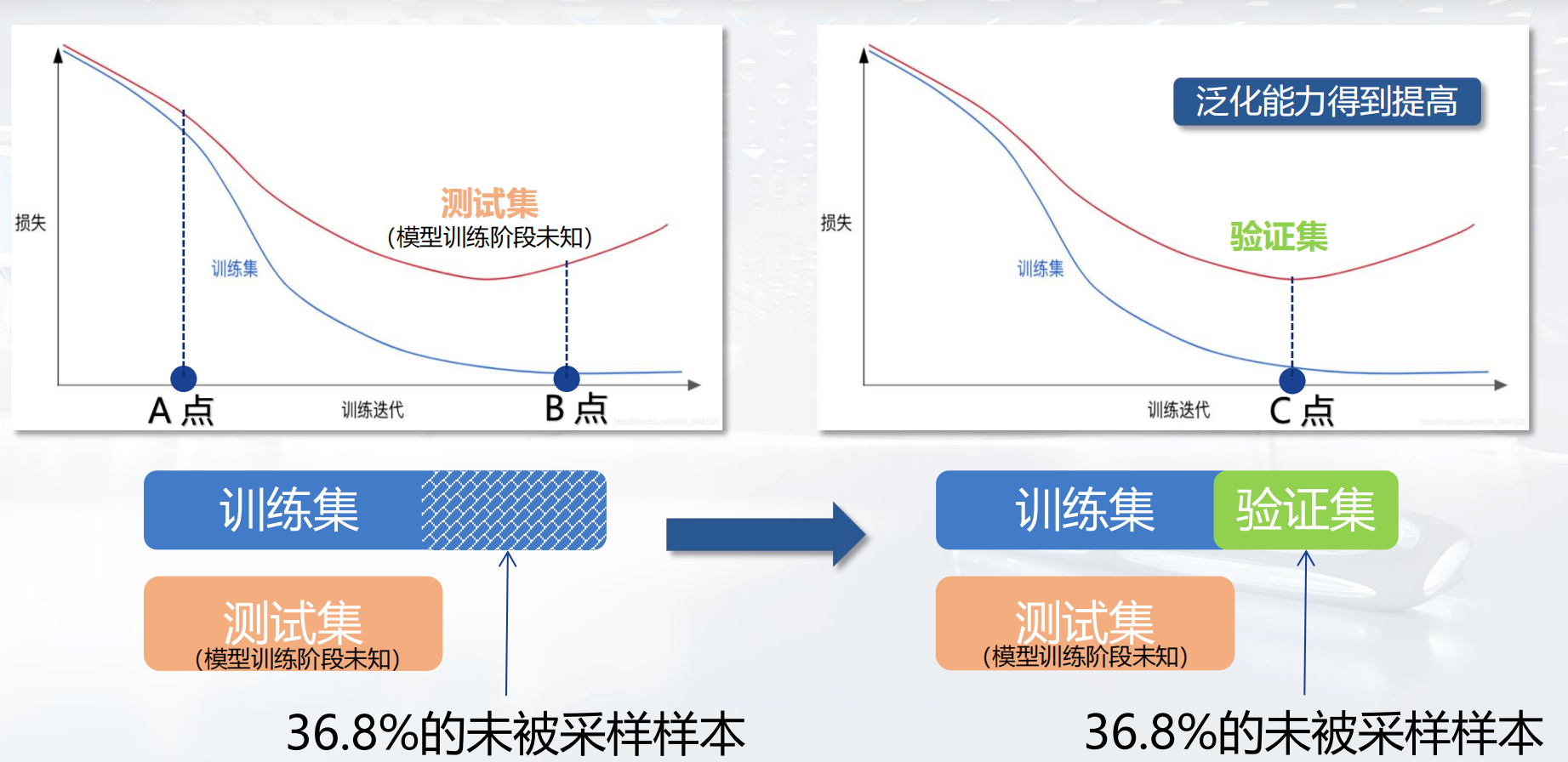
结合:
- 分类(对于分类问题)
- 投票法:若票数相同,则随机选择一个
- 回归(对于估计问题)
- 平均法
算法步骤:
- 使用自助抽样法,从训练集中做与样本容量相等的次数的采样。
- 利用采样集训练基学习器。
- 重复①、②,直到训练出T个模型。(并行化)
对于待预测数据,将得到的T个基学习器的结果结合。
稳定与不稳定算法:
- 不稳定的学习算法:训练集的微小变化会导致预测结果的巨大变化。
- 神经网络
- 决策树
- 回归树
- 线性回归中的子集选择
- 稳定的学习算法:
- K 近邻
Bagging总结: 对于不稳定的学习方法,Bagging是有效的;但是对于稳定的学习方法Bagging没有帮助。
随机森林(Random Forest)
算法步骤:
- 使用自助抽样法,从训练集中做与样本容量相等的次数的采样。
- 利用采样集训练模型(决策树)。
- 重复①、②,直到训练出T个模型。(并行化)
对于待预测数据,将得到的T个决策树的结果结合。
这是是装袋方法Bagging的一个扩展变体,以决策树来构建装袋方法Bagging,同时,在决策树的训练过程中引入了属性选择。随机森林中,随机选取一些 属性,在选取的属性子集中选择最优属性进行划分。
提升方法 Boosting
是一族可将弱学习器提升为强学习器的算法。
算法步骤:
- 先从初始训练集训练出一个基学习器。
- 根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注。
- 基于调整后的样本分布来训练下一个学习器。
- 如此重复进行,直至基学习器数目达到事先指定的值T。
- 最终将这T个基学习器进行加权结合。
个体学习器之间存在强依赖关系,必须串行生成的序列化方法。
自适应增强 AdaBoost(Adaptive boost)
是boosting算法中最著名的代表,数据挖掘十大算法之一。
特点:
- 不是重采样,而是使用训练集重加权
- 每个训练样本使用一个权重来确定其被选入训练集的概率。
- AdaBoost 是一种将 “简单”“弱” 分类器线性组合构建 “强” 分类器的算法
- 最终分类基于弱分类器的加权投票
算法步骤:
- 初始化样本分布权值
- 重复如下步骤
- 基于分布
从数据集 中训练出分类器 - 估计
的误差 - 确定分类器
的权重 - 更新样本分布
- 基于分布
- 直到满足
值,停止算法,返回结果
目标:
- 最终分类器
- 最小化损失
- 最小化边界框
Bagging和Boosting的对比
| Bagging | Boosting | |
|---|---|---|
| 基学习器训练数据 | 训练样本相同,但权重可能不同 | 训练集不同 |
| 并行计算 | 个体学习器之间存在强依赖关系,必须串行生成 | 个体学习器之间不在强依赖关系,可同时生成 |
| 结合 | 每个基分类器都有相应的权重,加权结合 | 简单投票/简单平均 |